
Let's optimize
01 Feb 2016I/O and CPU
We have seen in part #1 that my laptop is processing 30GB of deflated CSV in about 11 minutes. If we want to do better, the first step is find out what is our bottleneck. The code was presented in part #2.
For years, we have worked under the assumption that IO where the limiting
factor in data processing. With SSD and PCIe disks, all this has changed.
Believe me, or re-run the bench and look at top, it’s very obvious that we
are now CPU-bound.
Another simple way to convince us about this is to check out at what speed we can read our 30GB data:
11:35 ~/dev/github/dazone% cat data/text-deflate/5nodes/uservisits/* | pv > /dev/null
29GiB 0:00:46 [ 633MiB/s] [ <=> ]
If you did not know about pv, well, check it out. What we learn here is that
we manage very easily to read the files for our benchmark from disk in
46 seconds, at more than half a Gigabyte per second.
So we definitely have to look at what the CPUs are doing.
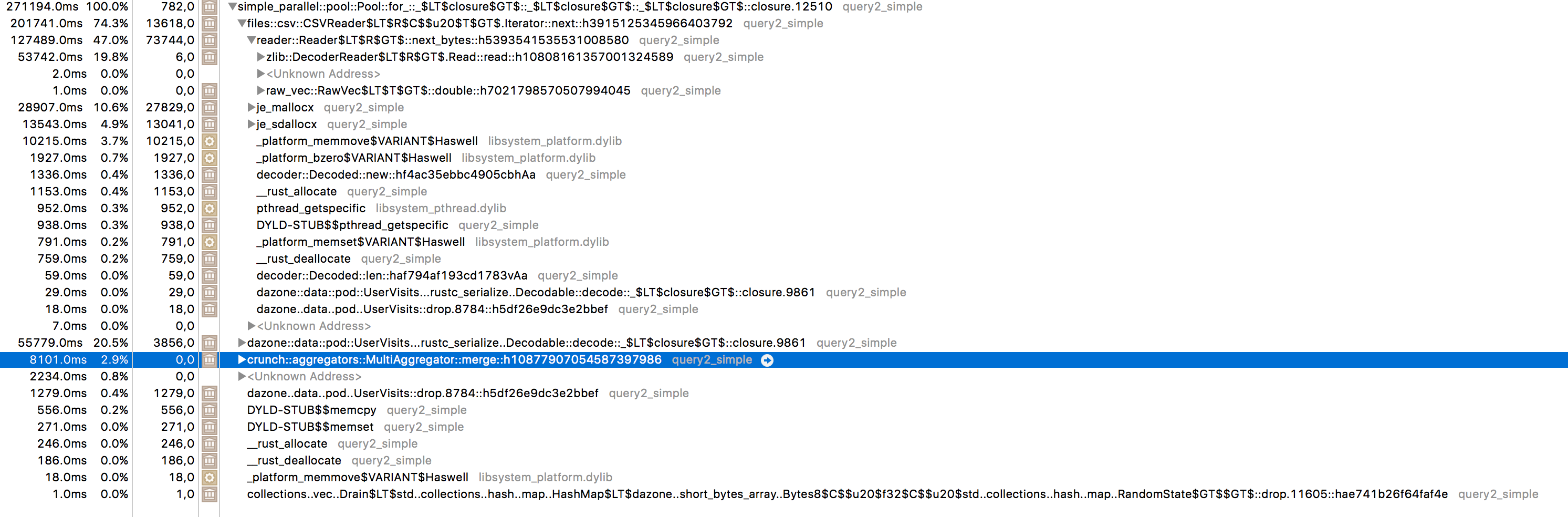
Without trying to decipher too much out of it, the four or five top lines show a lot a time is spent in CSV and Zlib functions. More “decoding stuff” appears just above the hilighted line (which is the actual final HashMap construction and is below 3% of the computing resources consumed).
A flamegraph will show it even better…

The fourth line (from the bottom) splits nicely the actual CPU load. From left to right:
- Inlet::push, weight 14%, and is about building partial results in each worker thread
- MultiHashMapInlet::drop, at 2.25% is where these partial results are merged to the total result
- finally at 82%, the main “map” function shows. Among it, worth noting are:
- a 15% cpu chunk eaten by inflate (decompression)
- a closure (fnfn) at 16% which seems about decoding data to POD
- also worth noting are about 9% spent in je_mallocx
All in all, not huge surprise.
Compression makes a lot of sense when I/O bandwidth is scarce and computing power is plentiful. But SSDs really have altered the equilibrium here (0.6 GB/s on a laptop…).
As for CSV, it is a human friendly format. It’s relatively easy to parse by eye (mostly due to the fact that each record is on its separate line). But it is an absolute horror to parse for a computer. As a matter of fact, most of the widely used data formats in data science are human readable, and terrible for performance: CSV, Json, XML.
It is still frown upon to use a binary format, but we will probably have to get used to it. Text formats are for Debug mode. HTTP is moving from a text format to a Binary format. We have been doing HTTP in Debug mode for 20 years, this is probably enough. Let’s grow up, develop tools to pretty print these new formats and protocols, and stop wasting so much computing power. Maybe we will save polar bears. At least, we’ll save some battery time.
Note that, as we try to find a better compromise for efficient data loading, we do not necessarily want to change the way data is put in long-term cold storage. It may be worth vaulting the data in highly compressed (bzip2) Json or XML or whatever format will be percieve as resilient to technology evolution, and use a separate, very loadable, probably binary, format to feed day-to-day data analysis.
Parser-friendly encoding
First, there is now a wide variety of binary Json-equivalent formats. They are schema-free, support string, numbers, boolean, and some form of list and map. BSON, MessagePack, bincode, CBOR happen to all have a ready-to-use rust encoder and decoder, so we can consider them as an alternative. It is relatively easy to design and implement these kind of formats, so there are many competing options today, and it’s a bit hard to guess which formats will still be around in a few years.
ProtoBuf and Cap’n Proto
Then, we have schema-full formats. They require the developer to write a format specification (think IDL) that the encoder and decoder will use to read and write the data, freeing it of the redundancy that comes with schema-free formats. There is a long and sometimes dark history here (yes, CORBA, I’m looking at you), so some people will get uncomfortable at the simple thought of IDL files. This is a bit of a shame. In the past decade, new formats have emerged from big organizations (Facebook, Google) and were deemed relevant enough to get some traction in open sources communities. They were originally targeted at message exchanging, but nothing prevents using them as storage formats. I have found off-the-shelf Rust support for Protocol Buffers, Thrift, and implemented a Protocol Buffers alternative in the bench.
ProtoBuf implementation is a departure from the POD approach: the IDL
defines its own data class, where each field is actually a placeholder:
native scalar values are wrapped in Option<> and String are wrapped
in a proprietary wrapper. So switching to ProtoBuf implies a bit more work
than POD-based RustEncoding or Serde encoders.
Cap’n Proto is a relatively recent development,
“infinitely faster” than Protobuf. It does
not use POD or near-POD struct, but rather provides generated Reader
and Builder that wrap a buffer to provide accessors to the actual data.
The buffer encoding does not contain pointers or architecture dependent
stuff, so it’s ready to be send, read, written or shared. No encoding
happens or decoding when loading a record. This is particularly relevant in our
case because we only use one string among the seven from the record.
As a matter of fact, Cap’n proto actually offers an optional “packed” encoding (where strings of zeros are collapsed togethers). But if we use a more sophisticated compression on top of Cap’n proto, it may or may not be useful. We’ll try both.
As for protobuf, we have to go through a proprietary interface to access the data, so the switch is not completely trivial.
Columing data
I have added one more “encoding” for a very simple not-even-proof-of-concept column storage scheme. This is very relevant here as we are only using two columns. It is called “buren”. If you don’t know why, you need to come and visit Paris.
Compression
Zlib-based formats are not the only option. Snappy and LZ4 may be relevant alternatives. Not compressing the data at all may also be an option, actually. I have not considered bzip2 as its computing requirement are even bigger than Zlib’s.
Plugging compression algorithms in and out of my code has been relatively painless, except for a few snags that I think are mostly due to the relative young age of the ecosystem: Rust having been stable for less than one year, library implementers are still working without a complete framework of good practise rules. Rust will get there with time, experience and discussion.
Results
This table have five groups of three columns, One group per compression scheme. From left to right, no compression, snappy, lz4, gz, zlib/deflate. For each group/compression scheme:
- disk is the data size, in GB.
- mbp is running time (in seconds) for my laptop: MacBook Pro, fall 2014, 16GB 2,8 GHz Intel Core i7)
- ovh is running time on a rented box at OVH, metal, not virtual, 32GB, eight cores
| format | disk | mbp | ovh | disk | mbp | ovh | disk | mbp | ovh | disk | mbp | ovh | disk | mbp | ovh | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| json | 213 | 855 | 461 | 55 | 815 | 481 | 51 | 756 | 471 | 33 | 1037 | 638 | 33 | 873 | 516 | ||||
| csv | 120 | 640 | 366 | 48 | 806 | 378 | 46 | 616 | 375 | 30 | 754 | 477 | 30 | 825 | 383 | ||||
| bincode | 150 | 377 | 202 | 50 | 552 | 214 | 46 | 377 | 208 | 33 | 547 | 335 | 33 | 551 | 263 | ||||
| mpack | 116 | 509 | 272 | 44 | 723 | 283 | 42 | 495 | 274 | 30 | 633 | 379 | 30 | 674 | 325 | ||||
| cbor | 186 | 1220 | 698 | 53 | 1564 | 708 | 48 | 1171 | 697 | 33 | 1361 | 847 | 33 | 1537 | 719 | ||||
| protobuf | 121 | 378 | 243 | 46 | 397 | 253 | 44 | 407 | 250 | 32 | 570 | 364 | 32 | 596 | 284 | ||||
| capnproto | 188 | 242 | 207 | 63 | 243 | 171 | 58 | 239 | 158 | 39 | 482 | 319 | 39 | 416 | 207 | ||||
| pcapnproto | 140 | 257 | 183 | 56 | 279 | 194 | 54 | 278 | 185 | 38 | 476 | 316 | 38 | 390 | 231 | ||||
| buren | 155 | 135 | 83 | 39 | 139 | 87 | 38 | 157 | 93 | 22 | 211 | 114 | 22 | 170 | 99 |
There are still holes in the table: a few combination I was not able to test or had widely inconsistent results. Remember that I’m running benches on a laptop, that this 1/ is not scientific at all, 2/ generates a lot of angry fan noise in my office (which is also my bedroom). As a matter of fact, all combinations in the mbp have not been treated fairly. I have made extra runs for the good perfoming combinations where I was basically leaving my laptop alone in a relative quiet state.
Or if you like bars… (shorter is faster)
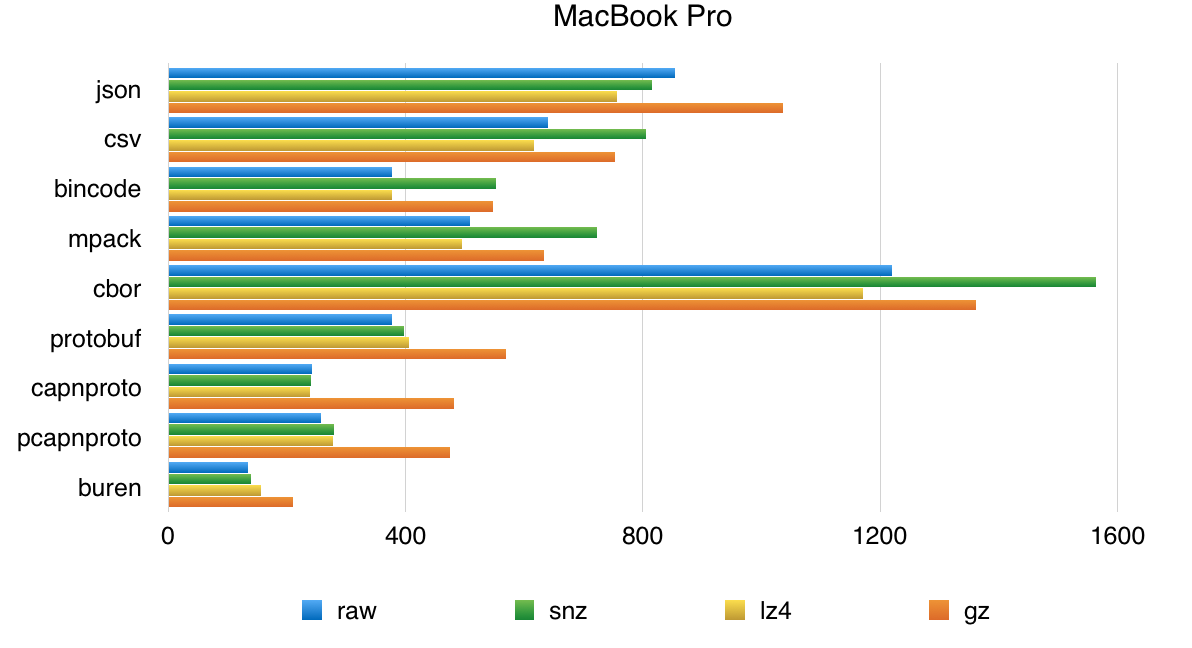
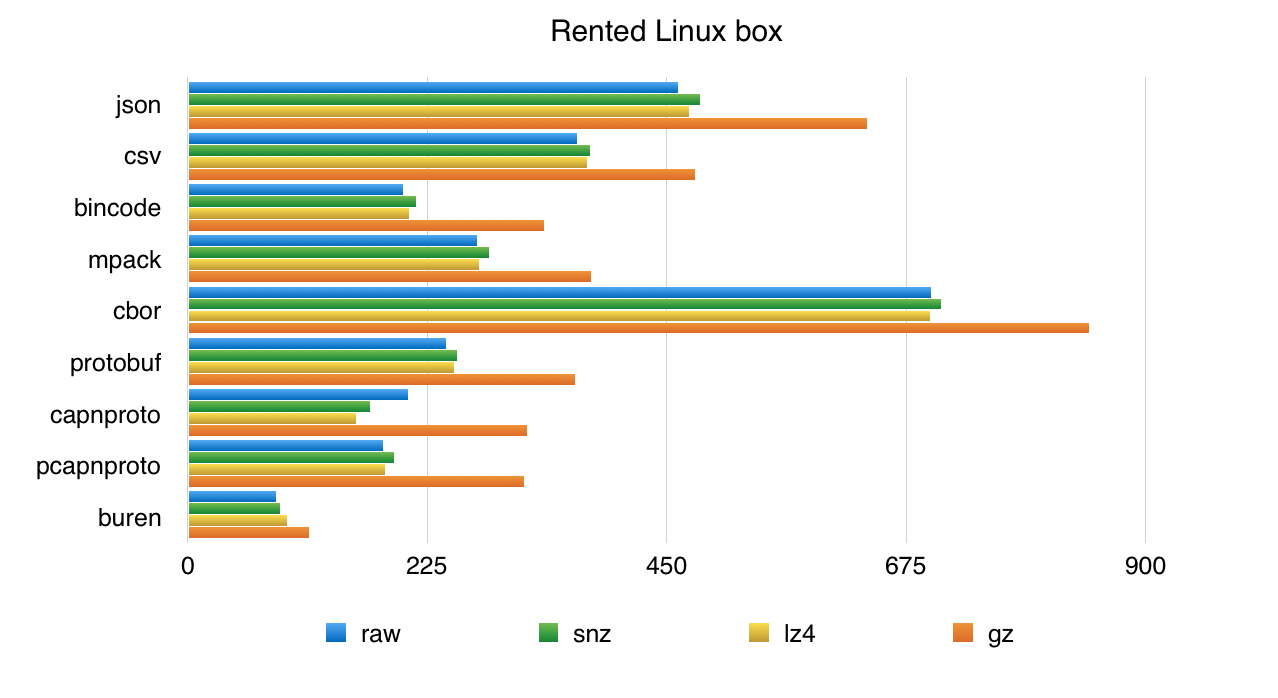
Anyway, I have highlighted a few “sweet spots” in the table. As I was writing earlier, Zlib is no longer a good choice.
Remarks:
- Buren, the ad-hoc column scheme is the best encoding here. It performs well, and it also compresses better than the row-based encodings.
- mpack is compact, bincode is fast… Both outperform the two text encodings.
- cbor looks very bad here. It generates bigger files than others binary encodings and performs poorly than Json. This was unexpected, and I have not looked into what is happening.
- capnp outperforms all other raw-oriented schemes. It works well with LZ4, but
also in non-compressed form. On the laptop, the packed variant of cap’n
proto works better than the unpacked. On the linux box, it is the other way
around. This is because the linux box has a higher io bandwidth/cpu
bandwidth ratio. Cap’n proto uncompressed on the laptop streams data at
760MB/s, slightly above the simple
pvmeasurement we did before. The same test on the linux box reaches 910MB/s (pvsays 930MB/s there). — I’ll be investigating about the linux box, I’m wondering if we could get a higher bandwidth by organising the RAID differently.
Cap’n Proto all the way
We can try one more thing. As Cap’n Proto can work with no encoding at all,
we can wrap its Reader on raw memory-mapped files, assuming there are in
then “not packed” form. This will only work in no zero-packing, no compression
form. As a matter of fact, to make it work, I had to add a “record size” header
between each record in the encoding, so the files are even bigger than the
non-compressed cap files. This will amount to 193GB (still smaller than Json)
and runs, on the laptop, in 261s. So this compromise is not particularly
relevant.
And the winner is…
So where are we now ? I have picked buren encoding and snappy compression. This is only marginally slower than uncompressed buren, and weights significantly less on my hard drive.

Now the big “map” stage, with all decoding, is 25% instead of 85%. There might still be possible improvements here: buren actually make copies of the textual data instead of borrowing it from the raw uncompressed buffer… malloc is at 2.6%, dalloc at 2%… But is it worth the trouble ?
Now the big chunk is the partial aggregation, at 64%. Is it some kind of low-hanging fruit we could grab here ?
Well, as a matter of fact, there is.
update_hashmap is the fonction that actually performs in-place aggregation
in the intermediary result, and later in the final result. Basically, it is
called with a key (a 8 to 12 bytes prefix, remember) and a float (the
ad_revenue). It will lookup the prefix in the hashmap, update the value by
adding the new revenue or just perform an insertion. This means we are
performing a lot of insertion in the HashMap. A simple instrumentation (
aka printf) showed me that in the case of Query2A, the partial map size
at merge time is in the 700-800. I also happen to know that growing HashMap
is expensive. So let’s try and create these HashMap at capacity instead of
letting them grow organically.
It takes us from 135 seconds to 80 seconds. Wow. That was worth a try. I honestly did not thought it could be so big an improvement. I double checked it and triple checked it, but here we go. Have a last flamegraph on me.

All this is for Query2A. Something fishy is happening with Query2C, I’ll need more time to get into what’s going on there.
Conclusion
So that was a big post, but we have gone a long way. We started at ~660 seconds and are now at 80 seconds. Let’s recap:
- use an efficient format. At least something binary, but consider columns.
- pick an efficient compression format. SSD means we are CPU-bound again. So we need something not CPU-greedy. LZ4 and Snappy look good.
- try obvious things, sometimes there are good surprises :)
- of course, use a profiler. They make nice graphes.
What’s next
Next post should be the one about running this on a — modest — cluster with timely dataflow, if I can get time on the cluster.
Rust and BigData series: